
“That’s making a big assumption.”
(This post is a follow-on from an earlier one.)
In the colloquial, the phrase means basing an argument on a precondition which is unusual or atypical or offends common sense.
When applied to scientific hypotheses, the term suggests the assumptions made are unusual or extraordinarily narrow, not justified by other evidence. In a way, such a claim itself is odd, for making assumptions is an important part of scientific model building. When Faraday did experiments in electrolysis, Stoney interpreted his experiments in terms of a smallest indivisible unit of charge, thereby postulating, without other evidence, the existence of the electron, something which was only discovered later by Thompson. Much of Physics and, I daresay, modern Biology is like this: Positing a mechanism arising from informed imagination for which otherwise there is no direct evidence, and then carrying on calculations showing its implications and especially its capability to explain the data at hand.
To illustrate and hopefully delineate what “making a big assumption” might mean, the question here is one raised in the context of Statistics: Can the “bigness” of an assumption be measured? This is certainly of interest in Statistics is another field where explanations live and die by the assumptions made. For instance, often, Gaussian distributions for measurements are assumed, for many good reasons, but the assumption is often not tested directly. (It should be tested directly, and there is an easy way to do just that.) But clearly it is of interest to other fields. And I will suggest how the bigness of an assumption might be measured. First, a digression.
Digression.
I have three favorite books concerning frequentist statistics. One, and probably my favorite, is the text by Kenneth Burnham and David Anderson, Model Selection and Multimodel Inference. (The other two are C.-E.Särndal, B.Swensson, J.Wretman, Model Assisted Survey Sampling, and S.N.Lahiri, Resampling Methods for Dependent Data.) Moreover, Burnham and Anderson’s text has no less than four R packages implementing its methods (MuMIn, glmulti, AICcmodavg, and MMIX).
Burnham and Anderson are advocates for an information theoretic approach to statistical modeling, and their Chapter 2 on the subject just shines. Even if they are frequentists, they are decidedly not advocates of null hypothesis testing (Section 2.11.5 of Chapter 2):
Tests of null hypotheses and information-theoretic approaches should not be used together; they are very different analysis paradigms. A very common mistake seen in the applied literature is to use AIC to rank the candidate models and then “test” to see whether the best model (the alternative hypothesis) is “significantly better” than the second-best model (the null hypothesis). This procedure is flawed, and we strongly recommend against it ….
Further, they state “Information-theoretic criteria are not a test” (Section 2.11.7, Chapter 2).
Their exposition of using the Kullback-Leibler divergence (“KL divergence”), first in terms of relating models to “the truth”, and then, second, showing how a relative divergence between models (Chapter 2, Section 2.1.2) is all that matters since “the truth” cannot be known, and then, third, showing how the Akaike information criterion follows from this argument (Chapter 2, Section 2.2). To see this in action, see Keil’s post or a Biostatistics 366 Python notebook illustration by Professor Chris Fonnesbeck. (Fonnesbeck has two nice expositions of Bayesian hierarchical modeling and MCMC diagnostics, too.)
Now, the KL divergence also has a meaning when applied to Bayesian inference. Specifically, when data from an experiment is received, and given a prior, the KL divergence can be applied to estimate the additional number of bits of Shannon information learned to obtain a posterior density given the prior and the data. This was shown by Lindley (1956) and Bernardo (1979).
End of digression.
Thus, moving on to the question at hand, I make the following suggestions. An assumption, 




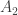

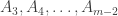

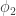
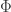

![\mathcal{D}_{KL}([x], [y]) \triangleq \sum_{i=1}^{N} [x_{i}] \log{\frac{[x_{i}]}{[y_{i}]}}](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BD%7D_%7BKL%7D%28%5Bx%5D%2C+%5By%5D%29+%5Ctriangleq+%5Csum_%7Bi%3D1%7D%5E%7BN%7D+%5Bx_%7Bi%7D%5D+%5Clog%7B%5Cfrac%7B%5Bx_%7Bi%7D%5D%7D%7B%5By_%7Bi%7D%5D%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
where I am using the notation ![[x_{i}]](https://s0.wp.com/latex.php?latex=%5Bx_%7Bi%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002)
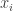
![[x]](https://s0.wp.com/latex.php?latex=%5Bx%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Thus, to claim that assumption 

What about models?
Can’t models have assumptions built into them? Yes, they can, and I argue a similar approach can be taken. In particular, in Bayesian inference, models are expressed in terms of likelihood functions for data, and each distinct model has a corresponding likelihood function. (There are sometimes called sampling densities in Bayesian work.) Essentially the existing apparatus of Bayes factors applies, interpreted strictly, for, as Burnham and Anderson point out in their information theoretic approach, it is invalid to compare models (or likelihoods) with one another using different datasets. (See their Section 2.11.1 in Chapter 2.) And the extention to Bayes means the same priors need to be assumed for both models. I believe any other approach founders on definitional matters, although I’d love to see proposals.
The Bayes factor approach is similar to the Burnham-Anderson one, except for the possibility that Bayes will have nuisance parameters integrated away. Burnham-Anderson, being frequentist, does not consider parameters as varying, for they are “part of the model”. Still, it’s clear how expectations of information can be taken with Bayes, giving a suitable Kullback-Leibler difference, just as in the case of different priors.
What about climate models?
Being a simulation of a complicated system, climate models have both boundary conditions, such as fixed time profiles of forcings from Sun, anthropogenic emissions of greenhouse gases, and volcanoes, and initial conditions, essentially starting points for the climate system. Because starting points are imperfectly observed, the state-space trajectory of a single climate model can differ appreciably if the model is initialized in a slightly different place in a hyperball about the observed starting point. This fact, which is really just a well known property of any mechanical simulation, means that the practice with climate models is to run them a great number of times using slightly different initial values. The “model” is then the ensemble of such runs. Other practices include making runs of different kinds of models, and either gathering these into superensembles or doing some kind of model averaging. It is possible to inform such averaging in a Bayesian way by doing hindcasting.
It’s clear that using the proposal above for statistical models could in some way be applied to individual climate models, those who have not been averaged together. There needs to be some kind of expectation taken over the ensemble generated from each run, and I feel that weighting each of them equally is probably a bad idea. Applying weights inversely proportional to the length of the perturbation hypervector in the initialization ball is the least that should be done. As a Bayesian, I’d like to get some additional weighting in by putting in an informed prior, but that strays from the purity of the simple formulation since, at one level, priors are being invoked yet, at the comparison point, they are not. What’s harder to imagine is what could possibly be used as the reference assumptions,
This is hard, for climate models incorporate some of the best science around. Sure, you can quibble with parts, and simplifications used to facilitate computing, but to do a quantitative assessment regarding plausibility of assumptions or how constrictive they are, it seems to me something like the above is needed.





Pingback: On nested equivalence classes of climate models, ordered by computational complexity | Hypergeometric